This week, Uber’s President and COO, Andrew Macdonald, said the company burned through its entire 2026 AI coding tools budget in just four months.
Microsoft also cancelled Claude Code licenses in one of its divisions, partly over cost.
What exactly is going on? Is AI dead on arrival?
Reframing AI Costs
From a high level, it seems the missing component is the link between spend and value. Macdonald said it himself: he can’t draw a clean line between the rising usage and features actually shipped.
This is a budgeting problem.
Many enterprises are lining up AI subscriptions for their team, not considering that it’s really metered compute and the costs really need to be broken down by workflow/agent/implementation.
Once you can see where the spend actually goes, the fixes become more obvious. They fall into three buckets.
Send Less, Get Less Back
Just because AI can do something doesn’t mean it’s best suited for the job.
Put another way, most expenses are in the tokens you didn’t need to burn.
There are plenty of other options for automation like n8n and Zapier, which can automate tasks without burning tokens through an LLM.
n8n in particular is interesting because of self hosting features, which can make it virtually free (outside of infrastructure costs).
With a strategically designed n8n flow, you can have nodes that clean and process data without ever touching your LLM tokens.
You can also incorporate nodes that call LLMs for specific steps that really do require a LLM.
An Example
I was doing some prospecting using a list that fit my Ideal Customer Profile (ICP). As part of this process, I wanted to use AI to help identify personalization patterns and craft outreach messaging.
The easy (and expensive) way to do this would be to just pass the entire list to my LLM and have it crank.
Instead, I used n8n to clean and trim the data, reducing the payload sent to the LLM by 85%.
The workflow looks like this:
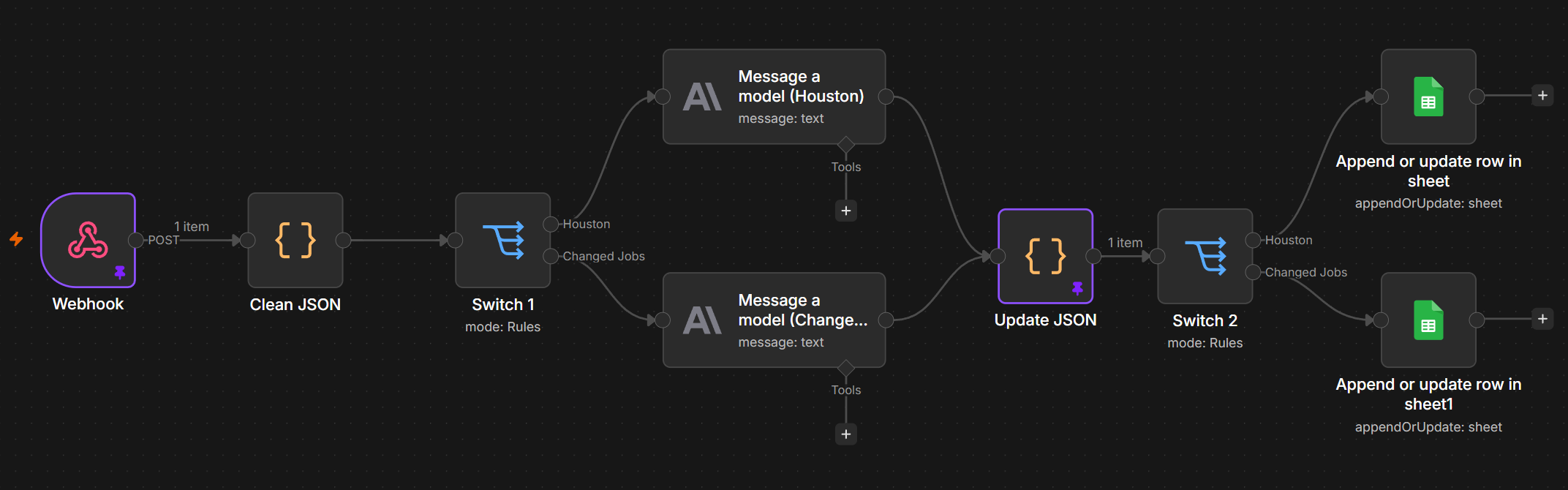
Within the two “LLM nodes”Message a model” nodes in this diagram, clear instructions are provided to the LLM so it knows exactly what to pass back; no more, no less.
A bit of upfront work in n8n let me process hundreds of records for a fraction of the cost of running it all through AI.
Reuse and Route
Another way to cut costs is through reuse and routing.
Reuse refers to two concepts: prompt caching and semantic caching.
With prompt caching, you’re being strategic about the parts of your prompt that stay the same across calls.
If you have a reference document that gets passed with every prompt, you can cache it so you’re not billed full price on that same block every single time.
The other option is semantic caching (beyond the scope of this article), where you store results from past prompts using a cheap embedding model, then compare future queries against the ones you’ve already answered.
If a new query is close enough to an old one, you skip the LLM entirely and return the stored answer.
Routing is about sending each task to the cheapest thing that can actually handle it. A few techniques here: model tiering, batching, and self-hosting.
Model tiering comes down to choosing the right model for the job.
Not all models are created equal. Some are better at math, some are better at crafting copy, and some are simply “good enough” for the task at a fraction of the cost of the high-end models.
The move is to route routine, high-volume work to a cheaper model and save the frontier model for the tasks that actually need it.
Batching means sending non-urgent jobs and accepting that they’ll come back later in exchange for a discount. Anthropic’s Batch API, for example, returns results within 24 hours at half price. Ideal for anything that doesn’t need an answer right away.
Finally, there’s self-hosting: running a small open-weight model on your own infrastructure. The per-token cost goes away and you’re essentially paying for the infrastructure it runs on.
Control the Loop
Agents are where budgets quietly spiral.
Unlike a single prompt where you ask a question and get an answer, an agent makes decisions on its own. It reasons, calls tools, retries, and iterates. Every one of those steps is a billable round trip to the model.
Without guardrails, an agent chasing a complex task can burn through more tokens in a single run than a hundred simple prompts.
The fix? Set boundaries.
That is, cap the number of iterations an agent can take before it stops or escalates. Add stop conditions so it doesn’t keep refining an answer that’s already good enough. Throttle how frequently it can hit the API.
These aren’t limitations on capability; instead, they’re cost controls. The same way you wouldn’t let a cloud server auto-scale infinitely without a spending cap, you shouldn’t let an agent loop without one either.
The bigger question is whether the step needs AI at all.
A lot of what gets routed to an LLM could be handled by an if/else statement, a lookup table, or a basic automation node. These are predictable, repeatable operations that don’t require judgment.
The way I think about it: build the workflow first, make it deterministic wherever possible, and then plug the LLM into the specific node that genuinely needs it. Everything else around it should just run.
The most expensive AI strategy is pointing a model at an entire process and saying “handle it.”
Conclusion
AI cost management is becoming its own discipline. The answer isn’t to spend less on AI, but instead, to spend smarter.
Build the workflow first, then make it predictable and repeatable wherever possible. Plug the LLM into the one node that genuinely needs it.
The companies that treat AI as an architecture problem will reap the benefits of AI without the massive costs.